はじめに
画像認識や物体検出の研究開発において、大量の動画、画像データを効率的に管理し、必要なシーンを素早く検索できる環境の構築は重要な課題となっています。従来の方法では、人間が一つ一つの動画を確認し、メタデータを付与する必要がありました。この作業は膨大な時間と労力を要し、プロジェクトの大きなボトルネックとなっていました。
例えば:
- 自動運転の開発には、様々な道路状況の映像データ
- セキュリティシステムには、異常検知のための監視映像
- 製造ラインの品質管理には、製品検査の画像データ
これらのデータを効率的に管理し、必要なシーンを素早く取り出せる環境がなければ、開発のスピードは大きく低下してしまいます。
本記事では、最新のChatGPTを活用して、この課題を解決する具体的な方法を解説します。動画データの自動解析から、検索可能なデータベースの構築まで、実装に必要な要素を詳しく見ていきましょう。
目次
実装手順
以下がChatGPTを使った画像データベース構築のパイプラインです。
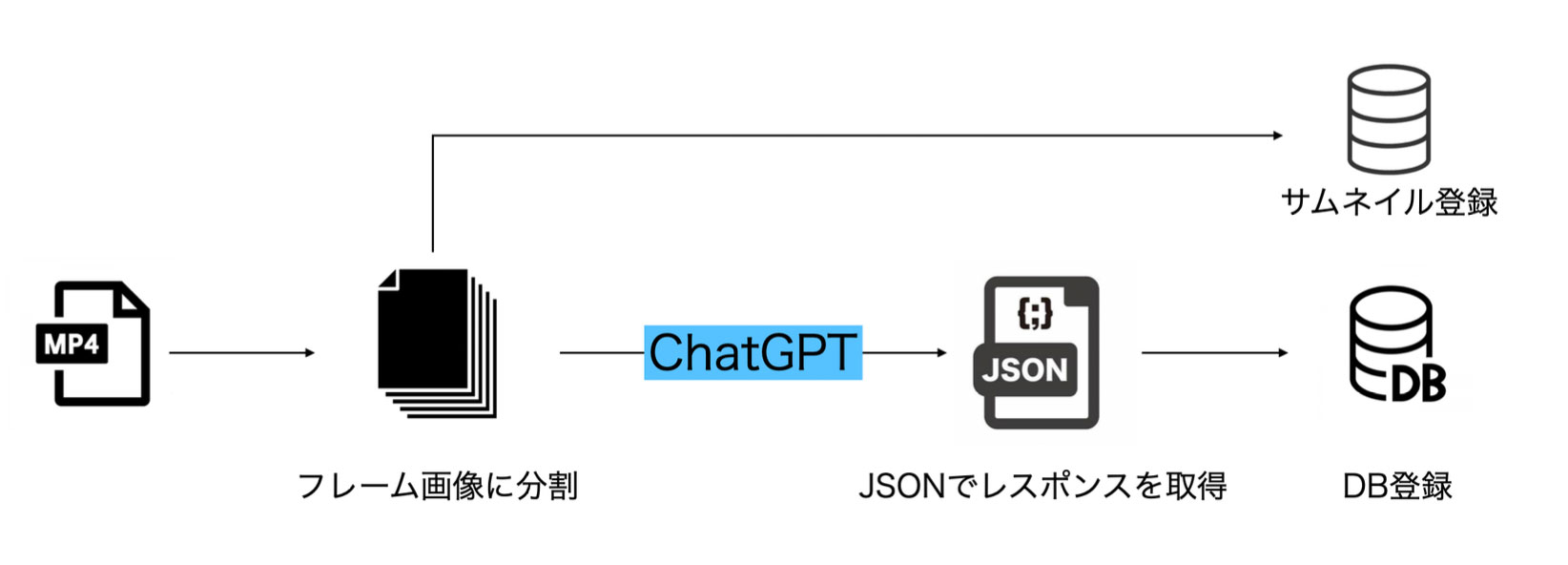
1. 動画のフレーム分割
まず、動画をフレーム画像に分割します。以下はPythonとOpenCVを使用した実装例です:
import cv2
import os
def extract_frames(video_path, output_dir, interval=30):
"""
動画からフレームを抽出する
Parameters:
video_path (str): 入力動画のパス
output_dir (str): 出力先ディレクトリ
interval (int): フレーム抽出間隔
"""
if not os.path.exists(output_dir):
os.makedirs(output_dir)
video = cv2.VideoCapture(video_path)
frame_count = 0
while True:
success, frame = video.read()
if not success:
break
if frame_count % interval == 0:
frame_path = os.path.join(
output_dir,
f'frame_{frame_count:06d}.jpg'
)
cv2.imwrite(frame_path, frame)
frame_count += 1
video.release()
2. ChatGPTによる画像認識
抽出したフレームに対して、物体検出を行います。ここでChatGPTが十分に力を発揮してくれます:
import base64
import os
import requests
import json
def encode_image(image_path):
try:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
except Exception as e:
print(f'Error encoding image at {image_path}: {e}')
return None
def build_payload(image_path):
base64_image = encode_image(image_path)
if base64_image:
payload = {
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
return payload
return None
def send_request_with_images(target_directory, api_key, endpoint_url, system_prompt, user_prompt):
image_files = [os.path.join(target_directory, file) for file in os.listdir(target_directory) if file.lower().endswith(('png', 'jpg', 'jpeg', 'bmp', 'gif'))]
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4o",
"messages": [
{"role": "system", "content": [{"type": "text", "text": system_prompt}]},
{"role": "user", "content": [{"type": "text", "text": user_prompt}]}
],
"max_tokens": 3000
}
payloads = []
for image_path in image_files:
payload = build_payload(image_path)
if payload:
payloads.append(payload)
if payloads:
payload["messages"][1]["content"].extend(payloads)
# APIへのリクエスト実行
response = requests.post(endpoint_url, headers=headers, json=payload)
if response.status_code == 200:
print("画像の要約が成功しました。")
json_data = response.json()
desc = json_data['choices'][0]['message']['content']
print(desc)
else:
print(f"画像の要約が失敗しました。ステータスコード: {response.status_code}")
try:
print(response.json())
except json.JSONDecodeError:
print("Failed to parse error response")
else:
print("有効な画像が見つかりませんでした。")
# 使用例
target_directory = "your_directory_path"
api_key = "your_api_key"
endpoint_url = "your_api_endpoint"
system_prompt = "Your system prompt here"
user_prompt = "Your user prompt here"
send_request_with_images(target_directory, api_key, endpoint_url, system_prompt, user_prompt)```
3. プロンプトについて
ChatGPTに映像を解析させるにあたり、以下のようなプロンプトを変数に格納してください。
system_promptの例:
役割とタスク
あなたは映像からシーンを解析する専門家です。あなたのタスクは、映像を切り出して時系列に並べられた画像群から、そのシーンが何かを予想し、詳しく説明することです。
与えられた動画の説明文を考えてください。ただし、この画像群は全体の映像の一部です。実際には前後に連続するシーンがあります。
user_promptの例:
以下に対象となる映像から切り出した複数のフレーム画像を時系列に添付します。
与えられたテキストと画像に基づいて、シーンの説明を生成してください。
ただし、説明文はいくつかの短いセンテンス内に収め、すべてのセンテンスは合計で300文字以下でなければなりません。
さらに、ChatGPT側にフォーマット変換すらぶん投げてしまうことも可能です。ユーザープロンプトに下記のような指示を入れると、JSONで戻ってくるのでそのままプログラムで処理してしまうことが可能です。
なお、フォーマットは以下の例のようなjsonとし、それ以外のフォーマットや説明文などは出力しないでください。
プレーンなテキストで「```〜```」といったマークアップを使用しないでください。
例)
{
"video_path": "path/to/video.mp4",
"frames": [
{
"description": "バイクが道路を走っています",
"time_code": "00:00:05"
},
{
"description": "バイクがバランスを崩しているように見えます",
"time_code": "00:01:20"
},
{
"description": "バイクが路上に転倒している様子が写っています",
"time_code": "00:01:25"
}
]
}
4. データベース登録
あとは出力されたJSONをお好きなように加工して、検索しやすいようにしていけばいいだけです。 MongoDBを使用した実装例:
from pymongo import MongoClient
def store_metadata(metadata, db_config):
"""
メタデータをMongoDBに保存する
Parameters:
metadata (dict): 保存するメタデータ
db_config (dict): データベース接続情報
"""
client = MongoClient(db_config['uri'])
db = client[db_config['database']]
collection = db[db_config['collection']]
result = collection.insert_one(metadata)
return result.inserted_id
まとめ
AIを活用した画像データベースの構築により、以下のような成果が期待できます:
- 処理時間の大幅削減: 手動処理と比べて90%以上の時間削減及び自動化、24時間稼働化
- 高精度な検索: 必要な画像への素早いアクセスとメタデータ管理
- スケーラブルな運用: データ量の増加に柔軟に対応
今後の展望
リアルタイム処理
- ストリーミングデータの即時処理
マルチモーダル分析
- 音声データとの統合
- テキストデータとの連携
本記事で紹介した方法は、あくまでも基本的な実装例です。実際の運用では、プロジェクトの要件に応じてカスタマイズが必要になるでしょう。しかし、この基本的なフレームワークを理解することで、より効率的な画像データベースの構築が可能になります。
実際に入力動画と出力結果などのサンプルをお見せすることもできます。 弊社ではこれらのAIを活用した開発効率化ソリューションをご提供しています。具体的な導入方法や、御社の開発プロセスに合わせたカスタマイズについてもご相談を承っております。